Working with Captures
A capture is a single extracted data record. Each run produces one capture per successfully extracted product page, containing structured ecommerce product data.
Browsing captures
• Dashboard
Navigate to Extract > Captures to view your extracted data.
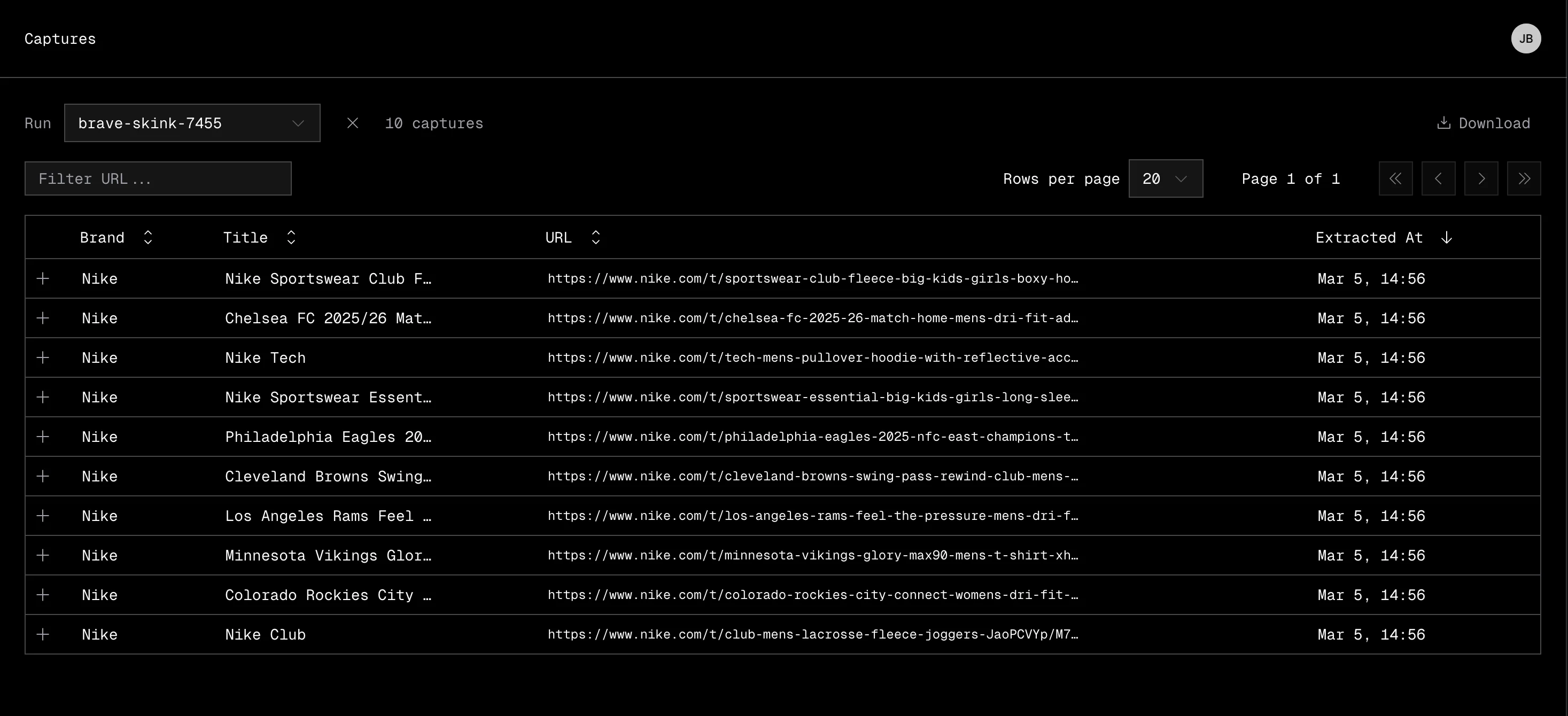
Use the filter dropdown to choose how to view captures:
- By run name: select a specific run to see its captures.
- By robot name: select a robot to see captures across all of its runs. An additional Run Name column appears so you can tell which run produced each capture.
The table displays Image, Brand, Title, Price, Available, SKUs, URL, and Extracted At for each capture.
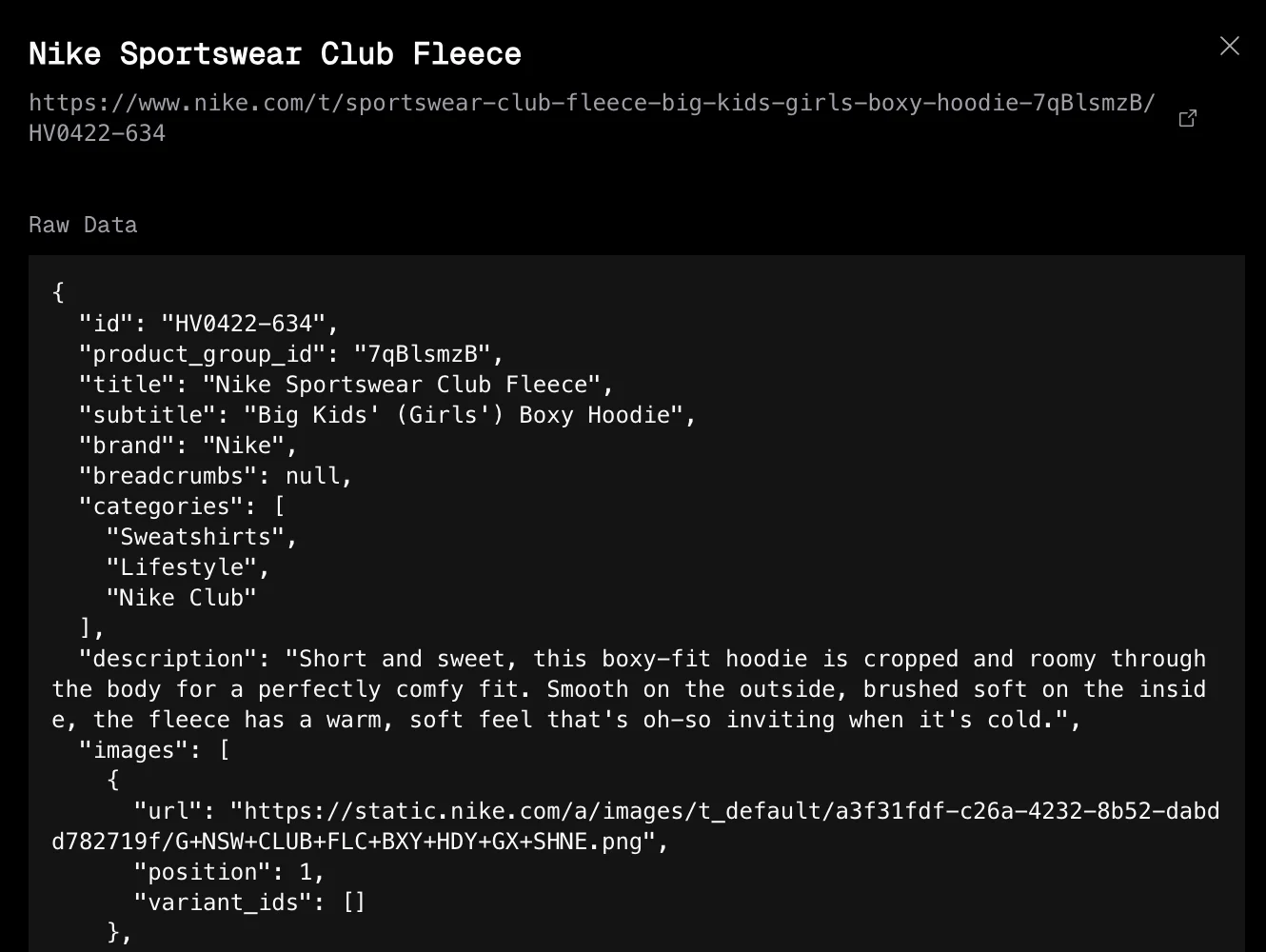
Click any row to open a detail panel with two tabs:
- Product — an interactive product page view showing images, options, pricing, description, and more.
- Raw Data — the full JSON extraction data with syntax highlighting.
• API
List captures from a specific run:
export EXTRALT_API_KEY="your-api-key"
curl -s "https://api.extralt.com/v0/extract/captures?run_id=$RUN_ID" \
-H "Authorization: Bearer $EXTRALT_API_KEY" | jqThe response is { rows, count, next_cursor, has_more }. The default page size is 100; up to 1000 with &limit=1000. See Common Patterns for paginating through large result sets with next_cursor.
Extraction data schema
Every capture contains structured product data. The same schema is used across all sites.
{
"id": "019d3ec3-cf96-7520-bc31-1474206e06ed",
"url": "https://www.nike.com/t/dna-mens-dri-fit-basketball-shorts-hVGm16/HV1878-350",
"extracted_at": 1774874512106,
"product_id": "HV1878-350",
"handle": "dna-mens-dri-fit-basketball-shorts-hVGm16",
"group_id": "hVGm16",
"title": "Nike DNA",
"subtitle": "Men's Dri-FIT Basketball Shorts",
"brand": "Nike",
"breadcrumbs": "Men > Basketball > Shorts",
"description": "Built for the court, ready for anywhere. These lightweight-yet-durable basketball shorts help keep you cool with our sweat-wicking Dri-FIT technology.",
"publication_date": "2025-10-02T07:00:00.000Z",
"gender": "MEN",
"age_group": "Adult",
"ratings_average": null,
"ratings_count": 0,
"ratings_scale": 5,
"min_price": 41.97,
"max_price": 41.97,
"currency": "USD",
"available": true,
"sku_count": 7,
"image_url": "https://static.nike.com/a/images/t_default/326dc2d4-a16d-4433-93d7-8d6f8313d4d0/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"categories": [
"Men",
"Basketball",
"Shorts"
],
"tags": [
"Basketball",
"Dri-FIT",
"Shorts",
"Men"
],
"images": [
{
"url": "https://static.nike.com/a/images/t_default/326dc2d4-a16d-4433-93d7-8d6f8313d4d0/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 1,
"sku_ids": [
"HV1878-350"
]
},
{
"url": "https://static.nike.com/a/images/t_default/e2c6c1aa-6d12-46b9-9385-d76bd4fa30e0/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 3,
"sku_ids": [
"HV1878-350"
]
},
{
"url": "https://static.nike.com/a/images/t_default/38d8c21c-c8dd-466b-949c-92fdfcd0320b/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 4,
"sku_ids": [
"HV1878-350"
]
},
{
"url": "https://static.nike.com/a/images/t_default/79d907aa-1763-4af7-a1bf-99f5fc30acc4/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 5,
"sku_ids": [
"HV1878-350"
]
},
{
"url": "https://static.nike.com/a/images/t_default/1cd3d1a3-fea9-4295-bf8a-f3d6d59f2d47/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 6,
"sku_ids": [
"HV1878-350"
]
},
{
"url": "https://static.nike.com/a/images/t_default/3cf19355-4f26-4faf-b658-581297b87e9c/M+NK+DF+DNA+8IN+SHORT+AOP.png",
"position": 7,
"sku_ids": [
"HV1878-350"
]
}
],
"videos": null,
"physical_measurements": null,
"properties_dict": {
"Style": "HV1878-350",
"Shown": "Chlorophyll/Black"
},
"properties_list": [
"Recycled Materials",
"Designed for Basketball",
"Unlined",
"Lightweight, sweat-wicking fabric with mesh and smooth interior",
"Side pockets and zippered utility pocket large enough for a phone",
"Elastic waistband with drawcord",
"Body: 100% polyester. Pocket bags: 100% polyester.",
"Machine wash",
"Imported",
"Shown: Chlorophyll/Black",
"Style: HV1878-350"
],
"options": {
"opt1": {
"name": "Color",
"values": [
"Chlorophyll/Black"
]
},
"opt2": {
"name": "Size",
"values": [
"S",
"M",
"L",
"XL",
"2XL",
"3XL",
"4XL"
]
},
"opt3": null
},
"skus": [
{
"id": "90c9f2c2-d984-5cc2-a2a0-89deac668eb3",
"title": null,
"identifiers": {
"gtin": "00198482162061",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "S",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": true,
"quantity": "In stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "032621f4-8f17-5716-932d-a93b0d1dfc4a",
"title": null,
"identifiers": {
"gtin": "00198481839179",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "M",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": true,
"quantity": "In stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "a73069dc-17b2-5dc7-b5cc-e78c9674d8cd",
"title": null,
"identifiers": {
"gtin": "00198481982455",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "L",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": true,
"quantity": "In stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "417e97e7-c31c-5ac0-999c-5b6779ba831d",
"title": null,
"identifiers": {
"gtin": "00198482264932",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "XL",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": true,
"quantity": "In stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "42484108-e343-520f-9ed1-1ca72a301174",
"title": null,
"identifiers": {
"gtin": "00198481731473",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "2XL",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": true,
"quantity": "Limited stock available"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "179d2b07-b59e-5a7d-912f-cebf81b1d13f",
"title": null,
"identifiers": {
"mpn": "HV1878-350",
"gtin": "00198482258597"
},
"opt1": "Chlorophyll/Black",
"opt2": "3XL",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": false,
"quantity": "Out of stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
},
{
"id": "fad73aae-e6b1-58ac-83a3-f17125c0b3b2",
"title": null,
"identifiers": {
"gtin": "00198482211318",
"mpn": "HV1878-350"
},
"opt1": "Chlorophyll/Black",
"opt2": "4XL",
"opt3": null,
"offers": [
{
"price": {
"amount": 41.97,
"full_amount": 60,
"currency": "USD"
},
"availability": {
"in_stock": false,
"quantity": "Out of stock"
},
"condition": "new",
"seller": "Nike",
"seller_type": "1p"
}
]
}
],
"recommended_products": [
"https://www.nike.com/t/mens-dri-fit-basketball-t-shirt-WPpZO1IN/HV1772-010",
"https://www.nike.com/t/victory-sunglasses-PP0tbC/DV2138-010",
"https://www.nike.com/t/brasilia-95-training-backpack-medium-24l-zz5tL7/DH7709-068",
"https://www.nike.com/t/ja-2-basketball-shoes-mkEicYoS/HQ8513-001",
"https://www.nike.com/t/mens-basketball-t-shirt-MRuIhbgt/IO9764-133",
"https://www.nike.com/t/dri-fit-club-structured-swoosh-cap-kxvJ3j/FB5625-222",
"https://www.nike.com/t/22oz-big-mouth-water-bottle-2VjPJW/N0000042-968",
"https://www.nike.com/t/lebron-witness-9-basketball-shoes-h9SkAFPT/II7520-100",
"https://www.nike.com/t/primary-mens-dri-fit-short-sleeve-versatile-top-XK77j1/DV9831-097",
"https://www.nike.com/t/utility-speed-backpack-27l-QnNg7P/FN4106-010",
"https://www.nike.com/t/everyday-playground-8-panel-basketball-gcWDgD/N1003082-816",
"https://www.nike.com/t/precision-7-easyon-mens-basketball-shoes-779glM/FN0324-101"
]
}Key fields:
| Field | Description |
|---|---|
product_id | Primary product identifier on the site (product handle, ASIN, etc.) |
group_id | Groups related captures for the same source product family (e.g., different color pages) |
title, brand, description | Core product identity |
image_url | Primary product image URL |
images | Product images with position and optional SKU association |
min_price, max_price, currency | Price range across all SKUs |
available | Whether any SKU is currently in stock |
sku_count | Total number of purchasable SKUs |
properties_dict | Structured attributes as key-value pairs (material, closure, etc.) |
properties_list | Unstructured features and claims (bullet points from the product page) |
ratings_average, ratings_count, ratings_scale | Rating metrics |
options | Up to 3 option axes (e.g., Color, Size) with all available values |
skus | One entry per purchasable option combination, each with identifiers and offers |
skus[].identifiers | GTIN, SKU, MPN, and other identifiers for this purchasable SKU |
skus[].offers | Price, availability, condition, and seller for each offer |
skus[].offers[].seller_type | 1p (marketplace selling directly), 3p (third-party seller), or null |
All fields are optional. What gets extracted depends on what the site exposes.
Exporting captures
• Dashboard
Once data is loaded, a download button appears in the filter bar. Click it and choose a format:
- JSONL: one JSON object per line, with fields for
id,url,title,extracted_at,robot_name,run_name, and the full product data. Good for scripting, analysis, and importing into other tools. - Parquet: columnar format preserving all capture fields. Ideal for data pipelines, DuckDB queries, and pandas DataFrames.
• API
For bulk download, use the export endpoint. It streams all captures from the run as a single file with Content-Disposition: attachment. The format query parameter accepts parquet (default) or jsonl.
# Parquet (default)
curl -sL "https://api.extralt.com/v0/extract/captures/export?run_id=$RUN_ID&format=parquet" \
-H "Authorization: Bearer $EXTRALT_API_KEY" \
-o captures.parquet
# JSONL
curl -sL "https://api.extralt.com/v0/extract/captures/export?run_id=$RUN_ID&format=jsonl" \
-H "Authorization: Bearer $EXTRALT_API_KEY" \
-o captures.jsonlRunning Extractions
Create runs to extract ecommerce data from any site, monitor extraction progress in real time, and download structured results.
Credits & Billing
Understand how Extralt credits work, manage your subscription, track usage, and optimize costs for ecommerce extraction, enrichment, and AI assistant usage.